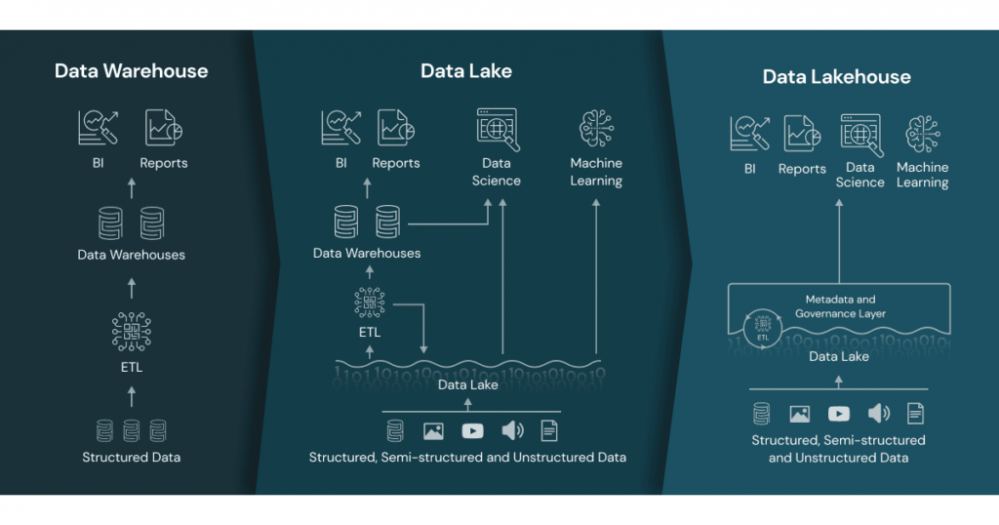
Ett Data Lakehouse kombinerar det bästa från Data Warehouse- och Data Lake-arkitekturerna i en och samma lösning.
En utmaning som de flesta organisationer har, är att de behöver kunna analysera olika typer av data, som kommer från många olika källor och i massiva volymer. En del data är strukturerad och ofta transaktionsbaserad, en del är semistrukturerad, till exempel e-post, och en del är ostrukturerad, till exempel: bilder eller video. Lakehouse-arkitekturen är en modern datalagrings- och analyslösning som kombinerar det bästa av tidigare lösningar: data lake och data warehouse för att dra nytta av deras respektive styrkor.
Data Warehouse
Datalager eller data warehouse’s är byggda för att lagra och bearbeta strukturerad eller semistrukturerad data för SQL-baserad analys och business intelligence. Datalager är mycket bra för strukturerad data, men moderna företag vill ofta även analysera ostrukturerad data, halvstrukturerad data, relatidsdata och inte minst i väldigt stora mängder. Datalager är inte lämpade för många av dessa användningsfall, och de är ofta inte de mest kostnadseffektiva.
Data Lake
En data lake är en billig, öppen, och hållbar lösning för alla datatyper: strukturerad, semistrukturerad och ostrukturerad. Vi ser ofta att stora mängder data av alla dessa typer lagras i data lakes i molnet. Detta tillvägagångssätt för att lagra data i öppna format till en låg kostnad har gjort det möjligt för organisationer att samla stora mängder data samtidigt som man undviker leverantörsinlåsning. Samtidigt har data lakes tre huvudproblem – säkerhet, datakvalitet och prestanda. Organisationer behöver ofta flytta data till andra system för att använda den, till exempel till ovan nämnda data warehouse. Kvalitet är också en utmaning eftersom det är svårt att förhindra datakorruption och hantera schemaändringar. Som ett resultat resulterar många av dessa data lakes i vad som kallas data swamps dvs ”dataträsk” i en direkt översättning.

Data Lakehouse
Data Lakehouse är en arkitektur som kombinerar de bästa elementen i data lake och data warehouse. Den möjliggör datastrukturer och datahanteringsfunktioner som motsvarar de som finns i ett data warehouse, och detta byggt ovanpå en kostnadseffektiv data lake. Ett data lakehouse ger dig fördelar så som dataversionering, governance, säkerhet och ACID -egenskaper som behövs även för ostrukturerad data. Genom att bygga ovanpå en data lake lagrar och hanterar ett data lakehouse all befintlig data i en data lake, oavsett datatyp. Lakehouse-arkitekturen stödjer också maskininlärning genom att ge direktåtkomst till data i olika format, och möjlighet att exekvera olika ML- och Python/R -bibliotek, till exempel PyTorch eller Tensorflow.
Nuvarande data lakehouse arkitektur sänker kostnaderna, men dess prestanda är inte på samma nivå som de man får med ett data warehouse. Vi tror dock att data lakehouse med tiden kommer att minska detta prestandaförsprång samtidigt som de behåller de goda egenskaperna att vara enklare, mer kostnadseffektiva och mer kapabla att integrera med olika typer av applikationer.
Summering
Kort sagt, ett data lakehouse är en lösning som kombinerar det styrkor från datalager med fördelarna från data lakes. Data lakehouse implementerar datalagrets datastrukturer och datahanteringsfunktioner från data lakes, som vanligtvis är mer kostnadseffektiva för datalagring. Data lakehouses är väldigt användbara för såväl data scientists som analytiker och data engineers eftersom de möjliggör dataintegration, maskininlärning och business intelligence i ett och samma system.